AI计算机
通算产品:
DAU-C100是软件定义、硬件加速、自主可控,针对提高CPU物理主机效率而设计的一款通用数据加速单元。通过卸载物理主机硬盘、内存、网卡等外设对计算资源的占用,减轻总线压力,可提升3~10倍IO性能,创新解决物理主机性能不足的问题。
型号 | 通用数据加速单元/ DAU–C100 |
配置参数 | •特性:加速CPU物理主机整机|CPU I/0卸载|信创适配空间|存储I/O加速|多芯融合|虚拟化、多租户、高可靠、高安全、弹性扩展、灵活易用等功能特性。 •硬盘管理能力:通过SFF8643接口从物理层面纳管服务器磁盘。 •自组网能力:3*25G SPF28光口,向下兼容10G。 •功耗:75W-135W。 |
外观设计 | •接口:标准 PCIE x8 接口。 •尺寸:全长,全高,双宽。 |
DAU-S100是专为提升物理主机I/O效率与整体安全性而设计。搭载自主研发的先进加速技术以及多重安全机制,加速物理主机的整体性能表现,增强数据存储与传输过程中的安全性,为企业的数据安全和稳定保驾护航。
型号 | 存储数据加速单元/ DAU–S100 |
配置参数 | •特性:具备加速CPU物理主机数据读/写|增强数据存储与传输安全|CPU I/0卸载|快照、备份|节点级高可靠|数据自动均衡/恢复|灵活扩展性|全协议多路径全活负载均衡数据读写模式|支持NUMA绑定|支持两地三中心架构。 •硬盘管理能力:通过SFF8643接口从物理层面纳管服务器磁盘。 •自组网能力:3*25G SPF28光口,向下兼容10G。 •功耗:75W-135W。 |
外观设计 | •接口:标准 PCIE x8 接口。 •尺寸:全长,全高,双宽。 |
DAU-C100与DAU-S100
DAU-C100 | DAU-S100 | |
CPU卸载 | √ | √ |
磁盘效率加速 | √ | √ |
适配空间 | √ | |
虚拟化 | √ | |
自组网能力 | √ | √ |
数据安全,多重防护 | √ | √ |
高速磁盘管理 | √ |
通过DAU-C100提升综合效能,有效降低总拥有成本(TCO)
传统信创 架构方案 | DAU-C100+信创架构 方案 | 说明 | |
成本对比 | 252万元/42台 | 128万元/(8台+8张DAU-C100) | 比传统信创方案节省49.2%(204万元/34台) 假设信创服务器6万元/台 |
能耗对比 | 24000W | 5400W | 比传统信创方案节省77.5%电力 |
机柜空间 | 84U | 16U | 比传统信创方案节省81%(68U空间) |
性能对比 | 满足性能 需求 | CPU、内存、网络、存储综合性能提升25%以上 | 比传统信创方案综合性能提升25%以上 |
业务兼容 | 差 | 高 |
DAU-C100
软件定义、硬件加速、自主可控的通用数据加速单元,具有迁移平滑高效、CPU卸载、I/O加速、多芯融合、轻量级虚拟化等功能特性。
通过DAU–S100加速,提升云桌面用户数,降低总拥有成本(TCO)
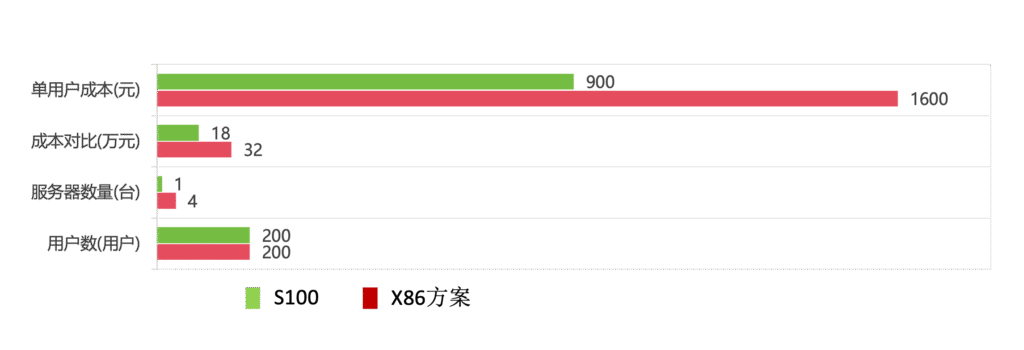
| X86方案 | DAU-S100+X86方案 | 说明 | |
| 成本对比 | 32万元/4台 | 18万元/(1台+1张DAU-S100) | 相同用户下,比X86方案成本节省43.75%(14万元) 假设X86服务器8万元/台 |
| 用户数 | 200用户 | 200用户 | |
| 单用户成本 | 1600元 | 900元 | 比X86方案单用户数节省43.75%(700元) |
智算产品:
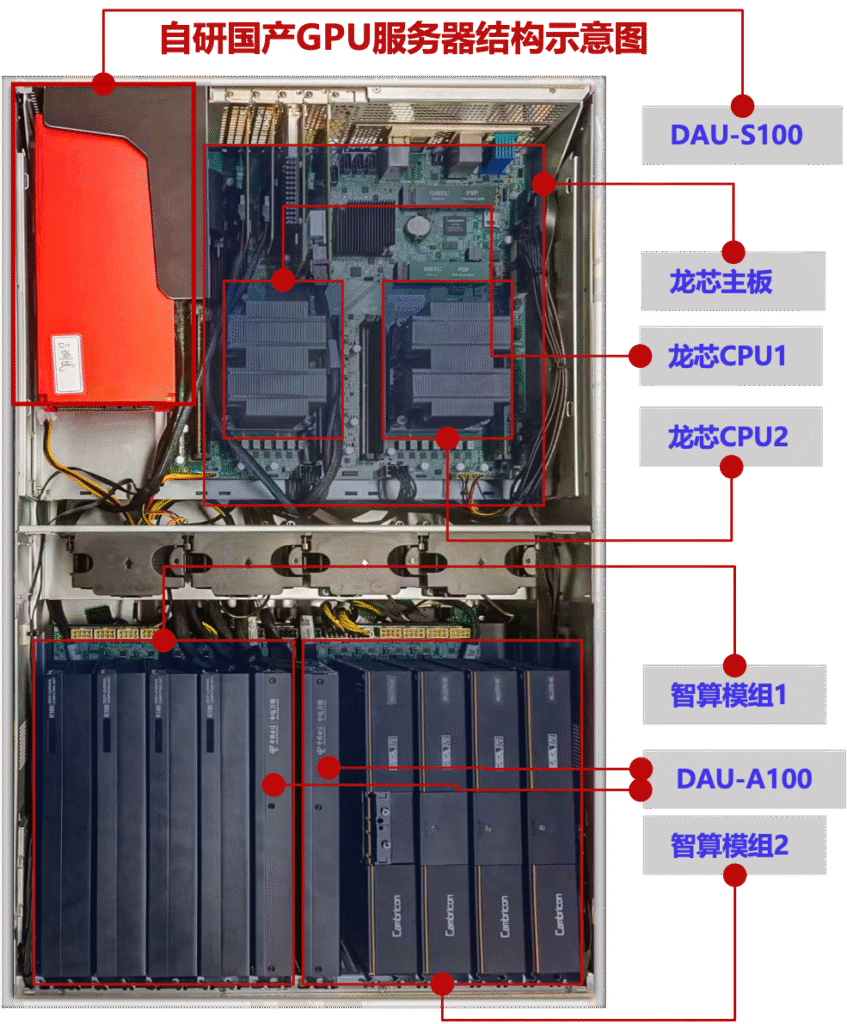
自研国产智算服务器(GAH)以龙芯为底座,核心是核心价值包,核心价值包包括自研智算扩展底板(EXT-1)+自研GPU数据加速单元(DAU-A100)+转接卡(A8-1)+自研存储数据加速单元(DAU-S100)四个部分。容芯致远国产GPU加速服务器基于核心价值包构建,可兼容国产主流GPU厂商产品,显著提升国产GPU算力效率。
智算服务器规格参数
型号 | GAH-A100J4L |
高度 | 4U 机架式服务器 |
处理器 | 2 颗龙芯3C5000 16 核处理器,2.0-2.2GHz,大容量三级缓存(128KB/256KB/32M) |
内存 | 8 根内存插槽,最大可扩展至512GB 内存 |
硬盘 | 前置支持12 块3.5/2.5 寸热插拔SATA/SAS/SSD 硬盘;内置置支持2 块m.2硬盘 |
网络 | 最大支持 4 个 100G 光口,2 个 10G 光口,3 个 25G 光口,2~4 个 1G 电口; |
GPU支持 | 最大支持8张国产GPU卡+2张DAU-A100+1张DAU-S100 |
算力效率提升 | 通过DAU-A100 加速后,整体算力效率提升40%以上; |
性能对比
模型 | 硬件 | 首次token平均延时 | 单个请求每秒token数 | 并发量 | 测试次数 |
Qwen1.5-14B-Chat | 4 * 华为910B | 322.68 | 21.66 | 100 | 10 |
1个智算模组 | 237 | 25 | 100 | 10 |
模型 | 硬件 | 首次token平均延时 | 单个请求每秒token数 | 并发量 | 测试次数 |
Qwen1.5-14B-Chat | 4 * 华为910B | 322.68 | 21.66 | 100 | 10 |
1个智算模组 | 237 | 25 | 100 | 10 |
通过测试结果分析,在实际模型推理中,智算模组具有性能优势。
智算服务器对比华为910B服务器整机具有性能优势。